 &imagePreview=1
&imagePreview=1
Written by Luca Csanády / Posted at 10/5/22
Synthetic data generation – beating the data challenge of automated driving
Data is critical to neural network (NN) development. Automatic annotation is the most effective and cheapest way to generate training and validation data from real-world recordings. But what about hard-to-capture scenarios or corner cases that hardly ever occur in real life? Automated driving systems still need to be aware of such events.
aiFab adds onto aiMotive’s proprietary simulation solution, aiSim. It is based on an aiMotive’s in-house developed, deterministic, physics-based, ISO26262 certified rendering engine, and it can be used to generate highly realistic, multi-modal ground truth to train and test perception solutions.
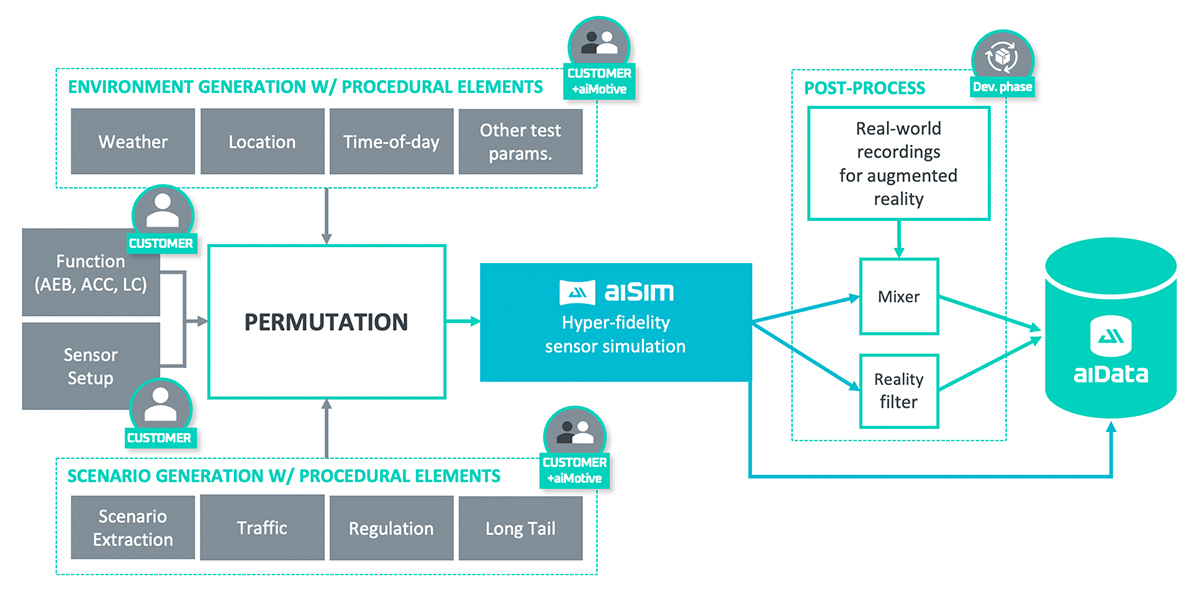
aiFab architecture
aiSim is a uniquely firm foundation for aiFab. One of aiSim’s key features is realistic sensor simulation with physically correct weather simulation. Sensor simulation is based on raytracing technology, allowing for hyper-fidelity, especially with no real-time constraints present during data generation. Moreover, the environment (including the weather) is consistent throughout all sensor modalities, allowing you to generate synthetic data for multi-modal perception solutions as well.
On top of this, aiFab provides tooling which makes it easier to use aiSim for synthetic data generation.
Firstly, it supports the simple generation of scenarios at scale, with domain randomization, to replicate the great variability in real world data. There are multiple ways for randomizing parameters, including Monte Carlo randomization and setting parameter constraints and dependencies. Such parameters may represent various properties of the scene, such as lateral and longitudinal offset, differential velocity, color, time of day, etc. Using equidistant or random sampling of the parameter space, a generic scenario template can be used to generate a massive variety of similar scenarios, but using slightly different parameters.
The generated scenarios can then be submitted to a rendering cluster for parallel processing, to enable rendering time to scale with the allocated rendering capacity, on-premise, or on demand in the cloud.
Once the data is generated, it provides various statistics and visual feedback on the generated data, so that the users can have a detailed understanding of what type of objects were in which locations in the world, under what conditions, and so on.
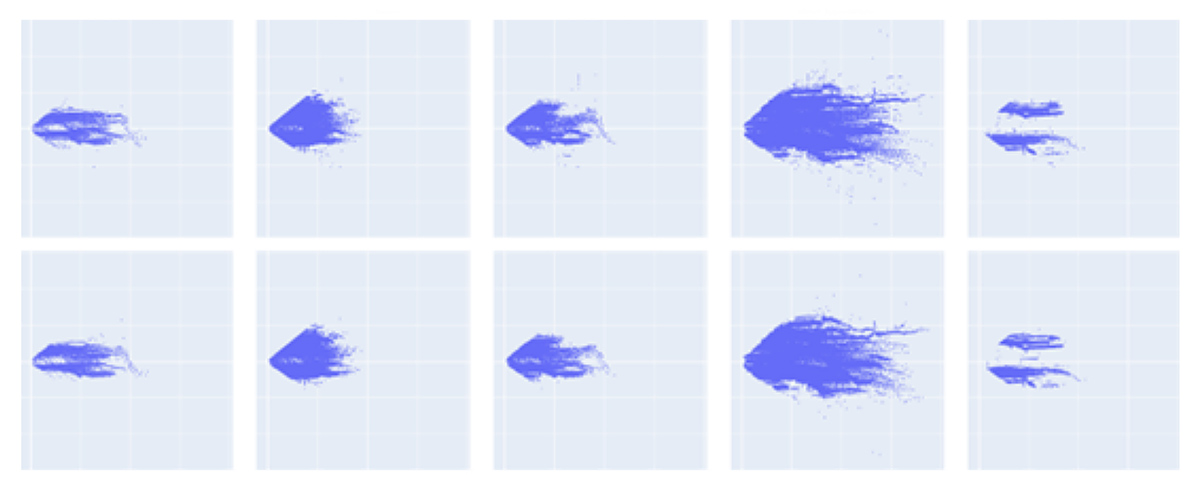
Object Position Scatter Plot
Furthermore, there are post process tools that make the generated data appear even more realistic to the perception neural network. aiMotive has developed an algorithm, known as a reality filter, which is responsible for altering the synthetic images in a way that makes them resemble real data for the NN, reducing the domain gap between real and synthetic datasets. It is also on our roadmap to extend its capabilities for further sensor modalities.

Sample image of an urban scenario with sun glare on lens
Benefits
Synthetic data has great use throughout the AD development pipeline.
First of all, it is an excellent way to quickly generate data for rapid prototyping. For instance, when you are developing a new detector for opened vehicle doors, within minutes you can generate thousands of frames containing such objects, under various weather, lighting, and traffic conditions, in a wide range of locations. You could very easily train and test your new algorithm, with minimal cost and effort.
It can also be used in various ways for perception development. We at aiMotive take advantage of artificial data by pre-training our auto-annotation network, aiNotate, which we introduced in our previous blogpost. This way, we can minimize the need for manual annotation, even if we extend our operational design domain or the set of annotated objects.
And most importantly, it is an indispensable tool for filling gaps in your training dataset. There are a wide range of scenarios that are extremely rare or almost impossible to capture in real life, so they remain underrepresented in the dataset used to train perception neural networks. To avoid false detections or undesired behavior, as well as to improve the NN’s perception performance in general, these scenarios can be generated by aiFab and used during the training process.
Outlook
Synthetic data indistinguishable from real life carries enormous value for anybody developing AD software. aiFab allows its users to generate the right data easily, quickly and inexpensively for their data needs. In our next blogpost, we will detail how we close the loop of AD software development with our metrics tool.
