Written by Mustafa Ali, András Juhász, Illés Sas / Posted at 6/19/25
Quantization that adapts to your hardware – not the other way around
Deploying high-accuracy neural networks on embedded systems is a major challenge. Developers are forced to balance performance, memory constraints, and power consumption – all while ensuring model accuracy remains intact. That’s where quantization-aware training (QAT) becomes essential.
At aiMotive, we’ve developed a new QAT method tailored for aiWare, our proprietary embedded NPU architecture. By integrating real hardware feedback into the training loop, we unlock better accuracy from INT8 quantized models – enabling scalable, high-efficiency inference at the edge.
Why quantization matters
Neural networks are typically trained and run in high-precision formats like FP32 (a 32-bit floating point number format). But for real-time, power-sensitive applications – like automated driving or embedded AI – these networks must be compressed to minimize hardware cost (number of compute resources, memory size, and bandwidth) by using lower precision formats such as INT8 or FP8.
This process, called quantization, significantly reduces compute, memory, and bandwidth demands. However, if done incorrectly, it can drastically impact accuracy.
To address this, two main techniques are used:
- Post-training quantization (PTQ): quick and easy, but can suffer from quality loss.
- Quantization-aware training (QAT): simulates quantization during training, producing more accurate results – if done right.
The problem with generic QAT
Most QAT implementations (e.g., PyTorch built-ins) apply generic noise models that don’t reflect the intricacies of your target hardware. But NPUs vary significantly – not just in number formats, but in internal dataflows, rounding schemes, and computation stages.
That’s why hardware-specific QAT is the key to unlocking maximum performance.
Our solution: aiWare-specific QAT
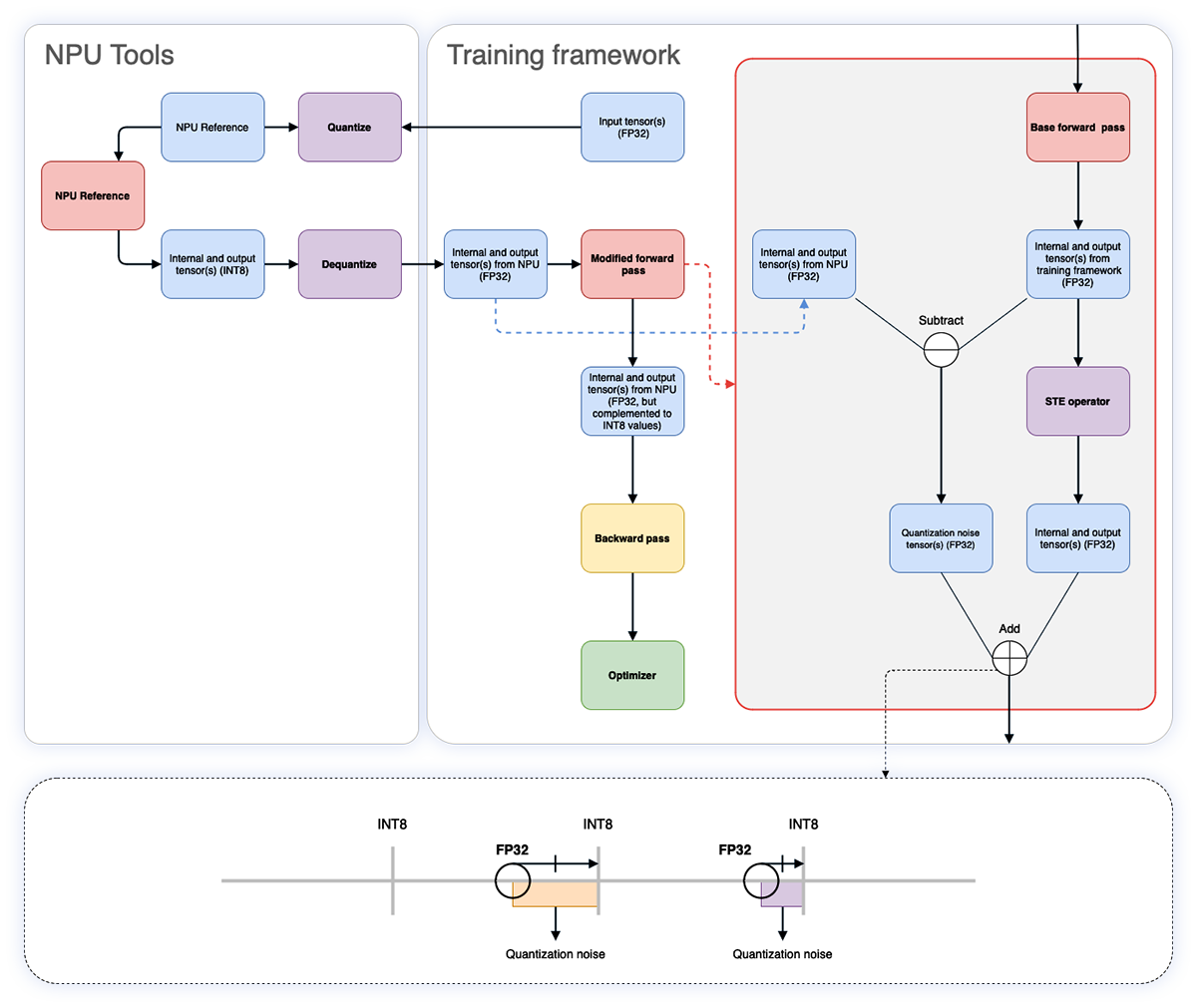
We created a QAT method that directly incorporates aiWare’s INT8 execution into the training process.
How it works:
- During training, the network runs in parallel:
- One pass uses FP32 in the framework (e.g., PyTorch)
- Another uses INT8 on the actual aiWare NPU
- We measure the quantization noise – the difference between INT8 and FP32 tensors
- This noise is injected into the FP32 training loop
- The model learns to adapt its weights and biases to the true behaviour of the NPU
The result?
- Accuracy is optimized as the quantized values come directly from the INT8 tensors of the NPU
- Fast training iterations using GPU accelerated aiWare model that utilizes the same compute infrastructure used for F32 inference
- Scalable and adaptable approach to changes in NPU architecture simply by using the appropriate NPU model.
Benchmarks
To evaluate the effectiveness of our QAT method, we benchmarked it on two neural networks for image classification on the ImageNet dataset which are known to be difficult to quantize. We compared the classification accuracy of four configurations:
- FP32 baseline – this serves as the reference point, using full 32-bit floating-point precision.
- Basic INT8 quantization – using a standard post-training quantization approach based on min-max scaling, this method exhibited a significant drop in accuracy compared to FP32, confirming the limitations of generic quantization.
- Framework-native QAT – PyTorch’s built-in QAT method improved accuracy over basic INT8 quantization but still showed measurable degradation relative to FP32.
- Our NPU-specific QAT – By directly modeling quantization noise from aiWare’s INT8 execution path, our approach achieved the highest accuracy among the quantized models. It consistently reduced the accuracy gap between FP32 and INT8, showing that fine-tuning with real NPU behaviour significantly improves inference results.
It is important to note that quantization results are very much neural network dependent. It is possible that a given approach works best for a particular network. The aiWare QAT method adds to the toolset of techniques available to aiWare developers optimizing their neural networks for achieving the highest performance without compromising accuracy.
What does this mean for you?
With our QAT technique, you get:
- Higher accuracy from quantized networks
- Reduced time spent tuning model conversion
- Optimized performance for aiWare – from day one!
Whether you are developing ADAS or AD features or edge AI solutions, this method helps you deliver faster, leaner models with no compromise on quality.
If you are interested in learning more or testing this in your own pipeline, reach out to us here.
