 &imagePreview=1
&imagePreview=1
Written by Tony King-Smith / Posted at 6/15/21
Efficiency, not Utilization or TOPS: why it matters
Technology leadership claims can often be “economical” with the truth, and this is particularly true for NPUs (Neural Processor Units). However, over-stated performance can lead to procurement decisions that fall short of expectations. The result is engineering targets missed, deadlines not met, and R&D costs escalating. For its aiWare NPU, aiMotive focuses on benchmarking NPU efficiency to provide the best information for AI engineers. Many other NPU suppliers quote raw TOPS and hardware utilization as a measure of performance. What’s the difference, and why does it matter?

“TOPS is misleading – it gives an extremely poor indication of the ability of an NPU to execute a real automotive inference workload. Hardware utilization isn’t much better – it is easy to claim high hardware utilization while still delivering poor NPU performance.” (Source: Marton Feher, SVP Hardware Engineering, aiMotive)
When is 10 TOPS not 10 TOPS?
Whether they have dedicated NPUs or not, most SoCs quote their capacity for executing NN workloads as TOPS: Tera Operations Per Second. This is simply the total number of arithmetic operations the NPU (or SoC as a whole) can in principle execute per second, whether all concentrated in a dedicated NPU, or distributed across multiple computation engines such as GPUs, CPU vector co-processors, or other accelerators.
This means if I have 5,000 multiplier units plus 5,000 addition units, and these are operated at a clock frequency of 1GHz, I can claim to have an NPU with a capacity of 10,000 GOPS (i.e., 10 TOPS). Since more than 98% of the execution operations of most automotive NN workloads is the calculation of convolution algorithms – which is almost entirely comprised of multiply plus accumulate operations – TOPS should in principle indicate how fast I can execute an NN.
Or does it?
No hardware execution engine executes every aspect of a complete NN workload with 100% efficiency. Some layers (such as pooling or activations) are mathematically very different to convolution. Other times data needs to be rearranged or moved from one place to another before the convolution itself (or execution of other layers such as pooling) can start. Other times the NPU might need to wait for new instructions or data from the host CPU controlling it. These and other operations will result in fewer computations being done than the theoretical maximum capacity.
Hardware utilization – not what it appears
Many NPU suppliers will quote hardware utilization to indicate how well their NPU executes a given NN workload. This basically says: “this is how much of the theoretical capacity of my NPU is being used to execute the NN workload”. Surely that tells me what I need to know?
Unfortunately, not. It is a bit like having an unproductive employee: they may appear to work hard, but are they doing the right job in the best way possible?
All NPU architectures use some hierarchical structure of “MACs” to form the underlying execution engine. A MAC (Multiplier plus Accumulator Unit) is a small execution unit comprising a multiplier circuit plus an adder circuit. Together these represent two “operations” or “OPS”, and these are then used to calculate the claimed TOPS for the NPU.
NPU designers often assemble arrays of smaller execution units – for example, matrix multipliers or vector processors - to build up the complete NPU capable of delivering the required raw processing horsepower. This gives us the claimed TOPS – usually the total number of MACs in the complete NPU, multiplied by their clock speed. For example, an NPU containing 1,024 MACs operating at 1GHz gives us a claimed 1 TOPS NPU.
The problem is that each mathematical operation - such as matrix multiplication and convolution – requires a different organization of input and output data arrays. For example, if an NPU’s data pipeline is designed to be very efficient performing matrix multiplication, it will almost certainly be less efficient calculating convolutions, as the dataflow is significantly different. That means the hardware data pipelines in the chip hardware will need to do additional work to reorder the data before and after computation of the core algorithm itself, during which time useful work cannot be performed. And since CNNs are highly data-intensive, any data reordering or movement, when multiplied for every MAC, can add up to a lot of extra operations that don’t actually have anything to do with executing the algorithm itself.
It’s a bit like organizing every child in a school to visit all their teachers in one evening. We could organize all of grade 1 teachers to be there first, then arrange all the children in age group. Flow of children and teachers would be very efficient, changing teachers whenever a new age group arrives and each child entering and leaving the room only once. However, what happens if the teachers were arranged by subject? If the children remained arranged by age group, each child would need to go in and out of the room multiple times to see each different subject’s teacher. That’s not so efficient, unless you organize the children by subject, not age.
Other factors also impact hardware utilization figures, depending on how the NPU vendor chooses to define “utilized”. Some NPU vendors might count all operations used to reorder or move data as “utilized”, while others may not. Other NPUs might count all MACs as being utilized when actually only one MAC within a vector or array of MACs is used a particular operation, because the rest of the MACs in that cluster are blocked from doing anything else.
With hardware utilization, the number depends entirely on how the NPU vendor chooses to define it.
Sometimes this leads to misleading statistics, as shown in Figure 1 below.
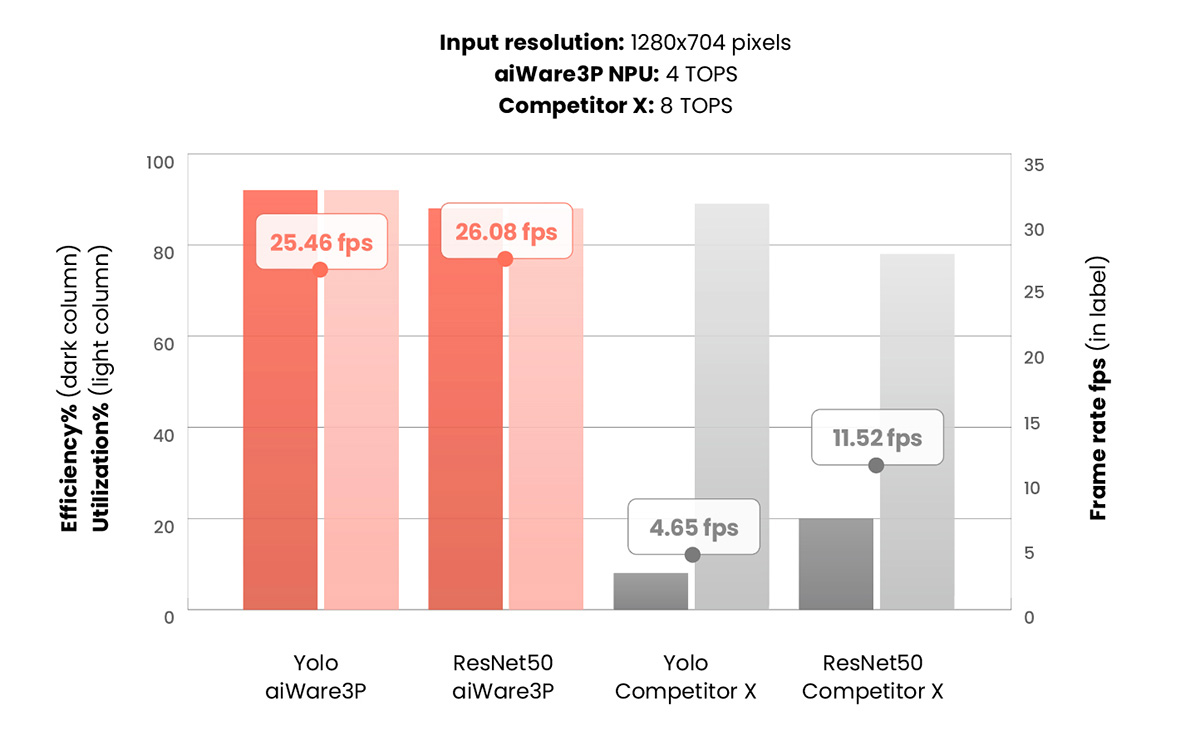
Figure 1: A leading automotive SoC vendor’s NPU delivers much lower performance than what is implied by the hardware utilization figures reported by their tools. Since aiWare was designed to maximize efficiency, it can deliver far higher performance for fewer claimed TOPS. (Source: aiMotive using publicly available hardware and software tools)
For two different well-known benchmarks, tools from a leading supplier of automotive SoCs report their NPU delivers high hardware utilization (light grey columns). However, their efficiency (dark grey columns) is much lower. Since Competitor X NPU claims 8 TOPS capacity, the hardware utilization would imply fps performance 2x higher than the 4 TOPS aiWare3P configuration used in the above comparison. However, the results show that aiWare delivers substantially higher fps performance (red dots) compared to the other vendor (grey dots) for the same CNN workload– despite having half the claimed TOPS capacity.
The conclusion: hardware utilization is almost as misleading as TOPS!
Efficiency – the right metric for embedded automotive AI applications
The problem with hardware utilization is that it is not related to the NN workload itself. aiMotive solves this by measuring efficiency. With efficiency, we start by calculating how many operations are needed to execute the CNN for one frame. This figure is calculated based solely on the underlying mathematical algorithms that define any CNN, regardless of how any hardware actually evaluates it.
Let’s say that we calculate our CNN requires 10 GOPS per frame. If we have a perfect NPU with a capacity of 1 TOPS, then that perfect NPU would achieve 100 fps (frames per second) when executing that particular CNN. However, no NPU is perfect, so will almost always achieve something less than the ideal 100 fps. So that’s how we define efficiency for a “real NPU”: the percentage of “real” vs “perfect” fps for a given NPU executing a CNN workload. So a 1 TOPS NPU achieving 90% efficiency when actually executing a 10 GOPS CNN will achieve 90fps, not 100fps.
Benchmarks based on efficiency therefore tell the engineer what performance they will achieve for each CNN measured. That gives the clearest indication of the suitability of an NPU for the expected workloads. But also, a NPU that demonstrates high efficiency means it will make the best use of every mm2 of silicon used to implement it, and that translates to lower chip cost and lower power consumption.
That is why all aiWare benchmark measurements show efficiency, not utilization.
Conclusions
Automotive AI engineers must focus on building production platforms capable of executing their algorithms reliably. They must also commit to their choice of hardware platform early in the design cycle, usually well before the final algorithms have been developed. The choice of NPU in any hardware platform is therefore a crucial decision, that must be made using the best information available. Neither TOPS nor hardware utilization are good measures on which to base this crucial decision.
Since aiWare was designed to perform automotive NN inference workloads with the lowest possible power consumption and best use of every mm2 of silicon from day one, the architects focused on ensuring that every clock cycle was doing useful work as much of the time as possible. Since most automotive NN inference workloads comprise more than 98% convolution, we did not use matrix multipliers, but instead designed a highly efficient NPU incorporating MAC-based execution engines designed to compute 2D and 3D convolutions with close to zero overhead. This ensures that aiWare can execute most automotive CNN inference workloads with 90%-98% efficiency.
Our benchmarks of many well-known automotive SoCs have shown efficiencies rarely higher than 50%, often much less (we have measured 15% down to <1%!). So if you are considering what NPU is right for your application, make sure you use efficiency as the key metric to assess the best performance.
See our benchmarks
We believe our benchmark document demonstrates that aiWare is the automotive industry’s most efficient NPU for a wide range of well-known industry benchmarks, and a number of more realistic automotive NN workloads derived from aiMotive’s own aiDrive NN algorithm team.
