 &imagePreview=1
&imagePreview=1
Written by Tamás Matuszka and Dániel Kozma / Posted at 9/23/22
aiMotive paper to be presented at a scientific conference in Vietnam
The paper titled 'A Novel Neural Network Training Method for Autonomous Driving Using Semi-Pseudo-Labels and 3D Data Augmentations' written by Tamás Matuszka and Dániel Kozma has been accepted to the 14th Asian Conference on Intelligent Information and Database Systems (Category B in the 2021 CORE conference rankings) and will be published in Springer's Lecture Notes in Artificial Intelligence. The work will be presented in Ho Chi Minh City, Vietnam, on November 28-30, 2022. The article introduces semi-pseudo-labels and 3D data augmentations to train a 3D object detection neural network on limited, inconsistent datasets. With the help of the proposed method, the researchers were able to train a convolutional neural network, significantly increasing its detection range compared to the training data distribution.
The task of 3D object detection requires high-quality annotations, which are hard to acquire and expensive to label, especially of distant objects. Consequently, several datasets do not include annotations at distances of over 100 meters, while an ADAS (Advanced Driver-Assistance System) must be able to perceive objects beyond this limit. The paper describes a solution for overcoming this limitation in training datasets.
The first contribution of the paper is the definition of 3D augmentations. Most 2D data augmentations are easy to generalize in three dimensions. However, zooming in or out changes the image scale, altering the position and egocentric orientation of annotated objects in 3D space too. A virtual-camera-based solution has been developed to deal with this problem. The method consists of a zoom-in/zoom-out step which makes it appear that objects are moving closer to or further from the ego car while the camera matrix is modified, ensuring the transformation in image space is consistent with the real-world space. The principal challenge in making 3D augmentation a viable solution is dealing with unannotated objects that appear in the image. Fig. 1 describes the effects of zoom augmentation where objects with and without annotations are depicted with blue and red rectangles, respectively.
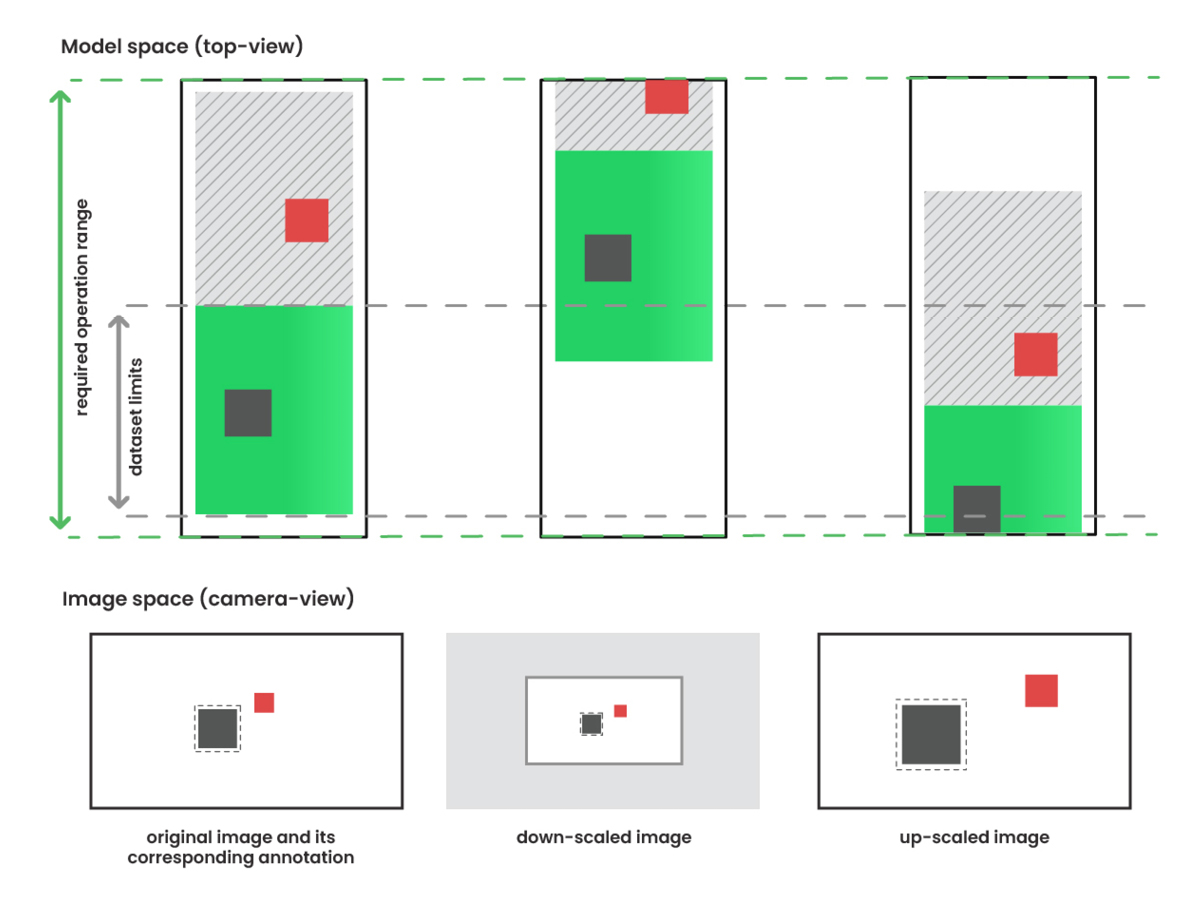 Fig. 1: Effects of zoom augmentation on image and model space data.
Fig. 1: Effects of zoom augmentation on image and model space data.
In this example, the object marked with the red rectangle is located beyond the limit of the annotation range hence there is no information even on the presence of the object, but it is still within the required operating range and visible on the image. Therefore, it cannot be used to supervise the loss. To provide a supervision signal for image-visible objects without 3D annotation, we introduced semi-pseudo-labeling (SPL) as a method where pseudo-labels are generated by a neural network trained on a simpler task and utilized during the training of another network performing a more complex task. For example, the output of a regular 2D object detector (i.e., semi-pseudo-labels) can be used to train a 3D detector. This method allowed us to utilize image-visible objects without 3D annotations during the training and thus significantly extend the detection range.
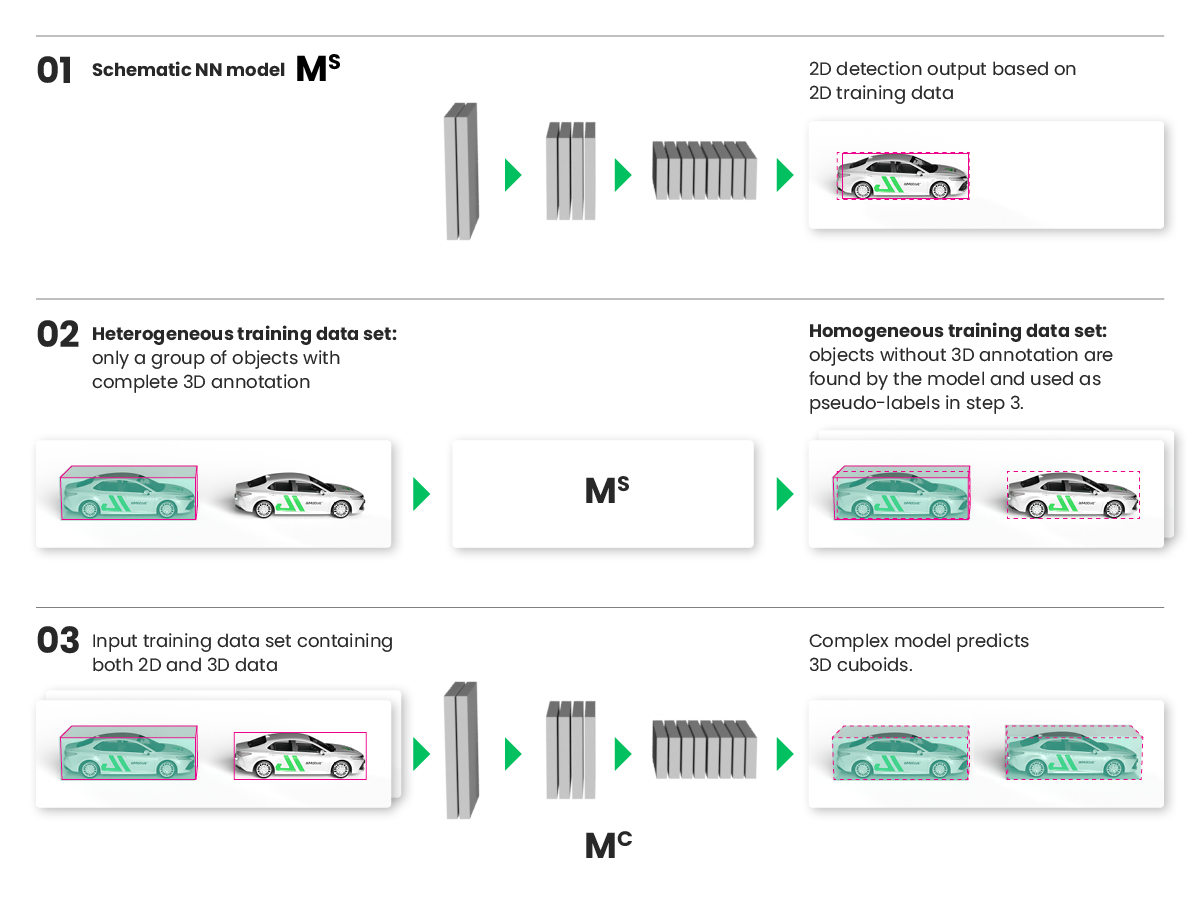 Fig. 2: SPL applied in 3D object detection using 2D detection as a simple task.
Fig. 2: SPL applied in 3D object detection using 2D detection as a simple task.
For further details regarding formal definitions, neural network architecture, implementation details, and experimental results, please read the preprint here.
