
Written by Tony King-Smith / Posted at 1/28/21
aiWare™ Studio: helping optimize algorithms, not accelerators
For embedded applications, the biggest challenge is taking a concept from a prototype in the lab to a production-ready solution: a product that is robust over lifetime, certified to all the relevant standards, tested to ensure it always works, and cost-engineered to make sure it delivers a profit. You need tools designed to help engineers do that job as flexibly as possible.
However, with AI-based systems, the intelligence of the solution lies in the design of the Neural Networks (NNs), not the code used to execute them. Any Neural Network Accelerator (NNA) is nothing more than the engine powering that intelligence.
That was the premise behind aiWare Studio: a unique tool for taking NNs from prototype to production by helping production engineers optimize the underlying AI to maximize the system performance, not just the low level code that executes it.
aiWare Studio is designed to enable automotive production AI teams to optimize and deploy NNs faster, with far greater flexibility.
Embedded AI: embedded software – but not as we know it
With any embedded software destined for deployment in volume production, an enormous amount of effort goes into the code once implementation of its core functionality has been completed and verified. This optimization phase is well understood by production embedded software engineers, but not so well recognized by research engineers focused on developing and training NNs in a lab environment.
So why shouldn’t you just treat NN software exactly the same way?
The biggest difference is that the functionality of the NN is not contained in the software itself, but within the topology of the NN, and the weights that have been carefully created through extensive training in a NN framework.
When you see a performance issue, such as a memory bandwidth bottleneck or poor utilization of the NNA, conventional embedded software techniques would encourage you to dig deep into the low-level code and find the problem. Your goal is to keep the same functionality, just make it execute better.
However with NNs, more substantial improvements will often be achieved by changing the NN itself, then re-train it. By changing how the NN implementation achieves the desired functionality, not just how we execute one implementation, we can achieve far better results.
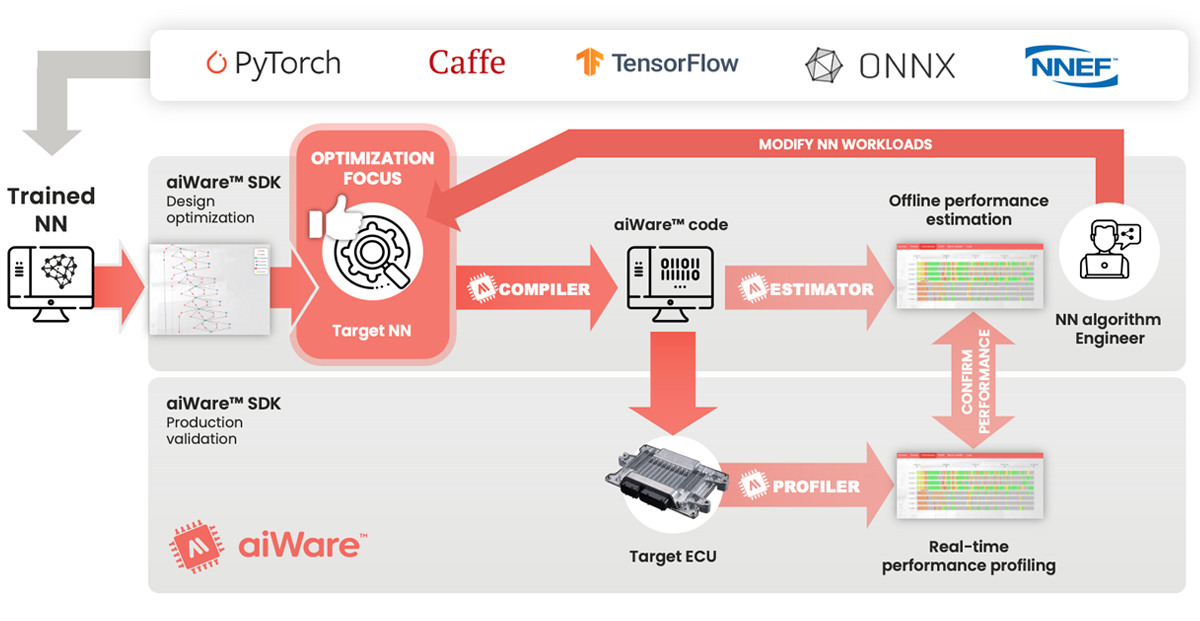
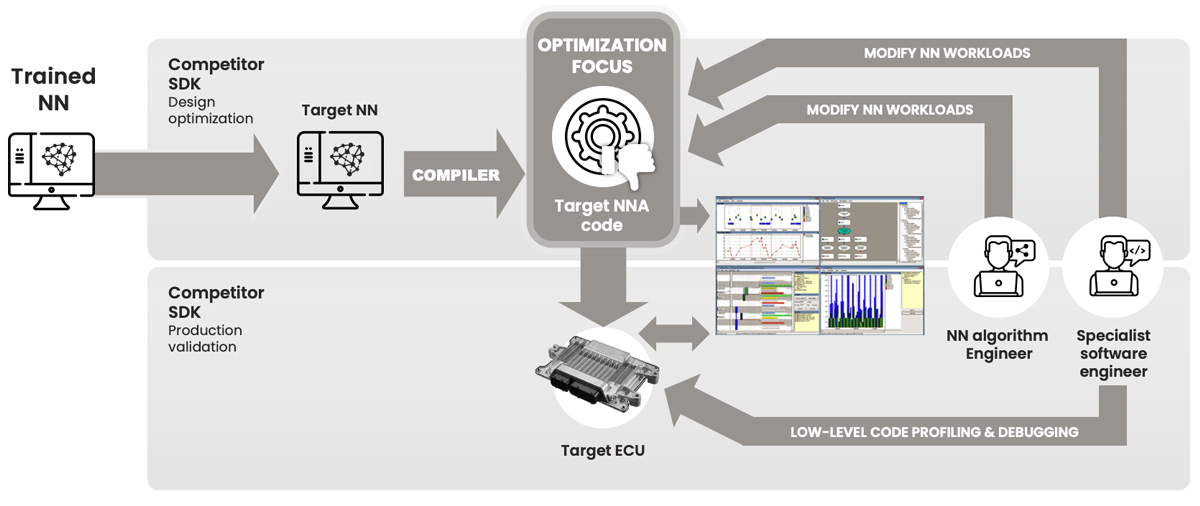
Figure 1: aiWare Studio enables users to optimize their NNs, rather than the code used to execute them. That gives AI designers far greater flexibility to achieve great results faster
Why would we do that? Because NNs are not like normal software. Since a well-designed NNA is designed primarily to execute NN functions such as convolution, pooling, activations etc, there is little point trying to make those low level functions work better. Most issues are more likely to be architectural within the NN topology itself. So the best place to tackle the problem is the underlying design of the NN itself. This gives the NN designer the greatest flexibility to make best possible use of the full set of capabilities of the NNA.
aiWare NNA + aiWare Studio: designed to do the job together
One of the reasons why the aiWare NNA is unique is because it is designed from the ground up to do only one job: execute CNNs for real-time automotive inference. That has resulted in an architecture where the lowest level hardware command is the execution of a complete layer function, since layer functions are the fundamental building blocks of any NN. Lowest latency, highest MAC utilization and lowest power consumption for any input resolution (scalable up to extremely high resolution sensors such as 8M and above cameras) were also key design goals. The way these commands are scheduled is at the heart of why aiWare can deliver such consistently high performance and utilization for a wide range of CNNs. And because data flow is tightly controlled at the layer level, not MAC level, the behaviour is 100% deterministic (other than external factors such as interfaces and memory subsystems).
These characteristics enabled the aiWare team to create aiWare Studio: a highly interactive set of tools for ingesting, compiling and analysing pre-trained NNs targeting automotive embedded hardware. Because the lowest level of command is a NN layer function, there is no need to profile or analyse tasks such as branch execution, caches, stacks, or myriad other low level tasks that you would expect to find in most DSP or MCU based hardware architectures. That’s because they do not exist: the compiler instructs the scheduler to deal with all data flow optimally.
That means users of aiWare Studio are focused not on execution of low level code, but only of the NN itself. Users can immediately see:
- How their NN progresses layer by layer through aiWare using the timeline
- How it allocates tasks to C-LAMS (dense arrays of MACs designed to execute directly convolutions and deconvolutions using kernels up to 11 x 11) and F-LAMs (smaller, more flexible functional execution units capable of executing most activation and pooling functions, as well as some smaller convolutions if needed)
- How many GMACs are required per layer, and how efficiently aiWare is delivering those GMACs for each function
- How much external memory bandwidth is being used per layer, and how efficiently that is being used
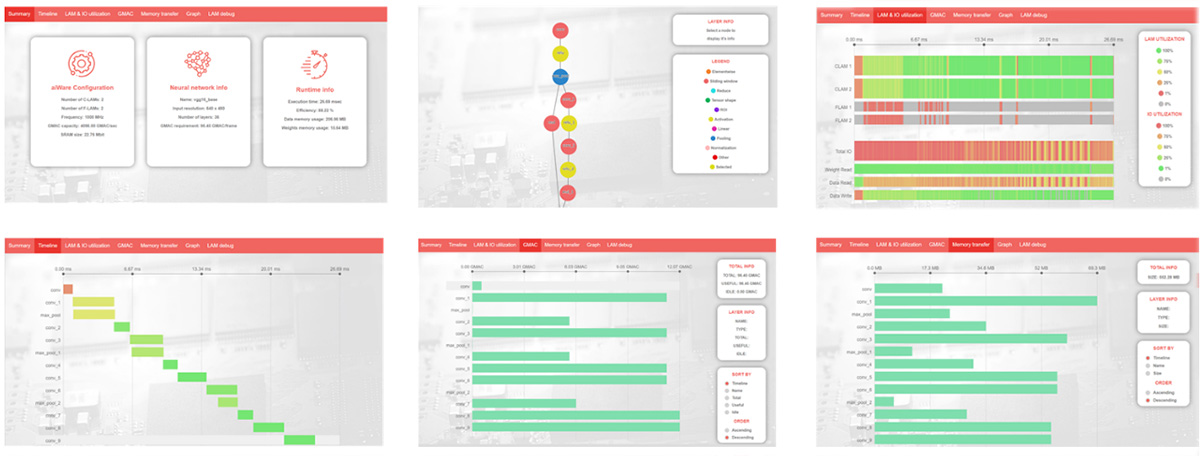
Figure 2: aiWare Studio provides a range of instant access tabs to provide several complementary views to illustrate how the NN is executing within aiWare
The language of aiWare Studio is NNs, not accelerator code. And since the functionality of the code is in the NNs, it enables designers to fine tune their designs with unprecedented speed.
Who needs hardware?
Another benefit of the highly deterministic architecture of aiWare is that we can accurately model its behaviour using high level models. Indeed, the compiler uses exactly that approach to ensure the final scheduling code is optimal. So if it is good enough for the optimizing compiler to use, why shouldn’t end users have access to that same model?
That’s what the aiWare Studio team have done with the offline performance estimation tool. Thanks to the offline performance estimation function, users of aiWare Studio can within a matter of minutes produce highly accurate estimations of how their NN will perform on any configuration of aiWare. This has been measured to be within 1%-5% of final silicon (excluding any memory subsystem factors, though they can be modelled as well). Since this environment executes on any PC, the tools can be used by engineers anywhere to help them create highly optimized CNNs targeting aiWare, without ever needing to get anywhere near a development board or hardware prototype.
Final checks
Of course it is vital to measure the final hardware when chips and hardware prototypes become available. The real-time hardware profiling capabilities of aiWare Studio have been designed to access a series of deeply embedded hardware registers and counters within every aiWare NNA implementation. While the silicon overhead is modest, they enable unprecedented, non-intrusive measurement of real-time performance during execution. This can then be used to compare directly against the offline performance estimator results, to confirm accuracy.
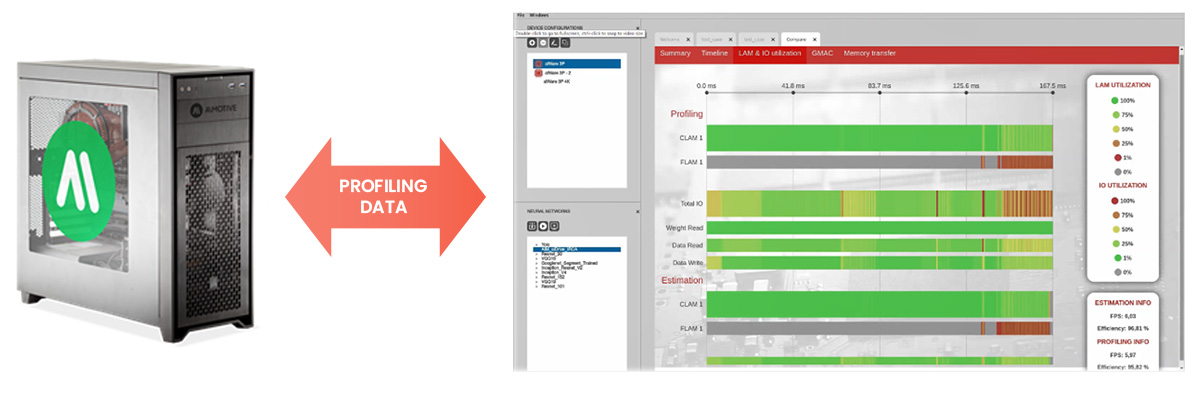
Figure 3: using embedded registers and counters, aiWare Studio can accurately measure final chip performance and compare it to the offline estimated results, which usually match to within 1%-5%
Conclusions
The new aiWare Studio Evaluation Edition is available for aiWare customers now. OEMs and Tier1s are also evaluating aiWare Studio to see how these unique tools can be used to help them design better CNNs for automotive applications. Because aiWare technology has been designed from the ground up to do the best possible job for executing automotive CNNs, especially for tasks requiring large inputs such as multiple HD cameras or sensor fusion, aiMotive has been able to offer the automotive industry a new and better way to develop, optimize and deploy AI in production vehicles.
Furthermore, aiWare Studio has enabled our aiDrive software team, who develop a wide range of CNNs for our customers, to develop our own NNs faster and more effectively. But perhaps more importantly, it has also enabled us to bring together our NN expertise with our customers’ in new and exciting ways, enabling a far more interactive, dynamic and collaborative way of developing AI for all of aiMotive’s customers.
